Building a Modern Machine Learning Platform with Ray
August 29, 2023


At Samsara, our philosophy is to empower scientists to be “full-stack” machine learning developers — which means scientists not only develop models but also operate what they build. This is a paradigm shift compared to the traditional setup, where there are usually separate teams to handle data preparation, model development, and production operations.The traditional setup, while maximizing efficiency in each sub-domain, also has significant drawbacks. To name a few:
Narrow vision promotes finger-pointing — Teams are motivated to create tools that solve problems in one stage well but fail to provide a productive experience for the entire machine learning lifecycle. Optimizing the end-to-end experience is always “the other team’s problem.”
High coordination overhead — Teams may end up blocking each other due to conflicting mandates and priorities, even when the tasks themselves are relatively easy to accomplish. For instance, scientists might need to wait on ETL changes to finish their EDA cycle or on engineering resources to create dashboards for monitoring. These negative patterns are observed by other practitioners in the industry as well [1].
To break down silos, we believe it is crucial to let people who intimately understand the nuances of models also lead the operational aspects of the machine learning project, which include: 1) How and when to scale up data collection and experimentation, 2) What is the evaluation strategy (i.e., offline vs. online) for different failure patterns, and 3) What data should be logged from production systems, and how they should be logged to build a ML developer friendly feedback loop.
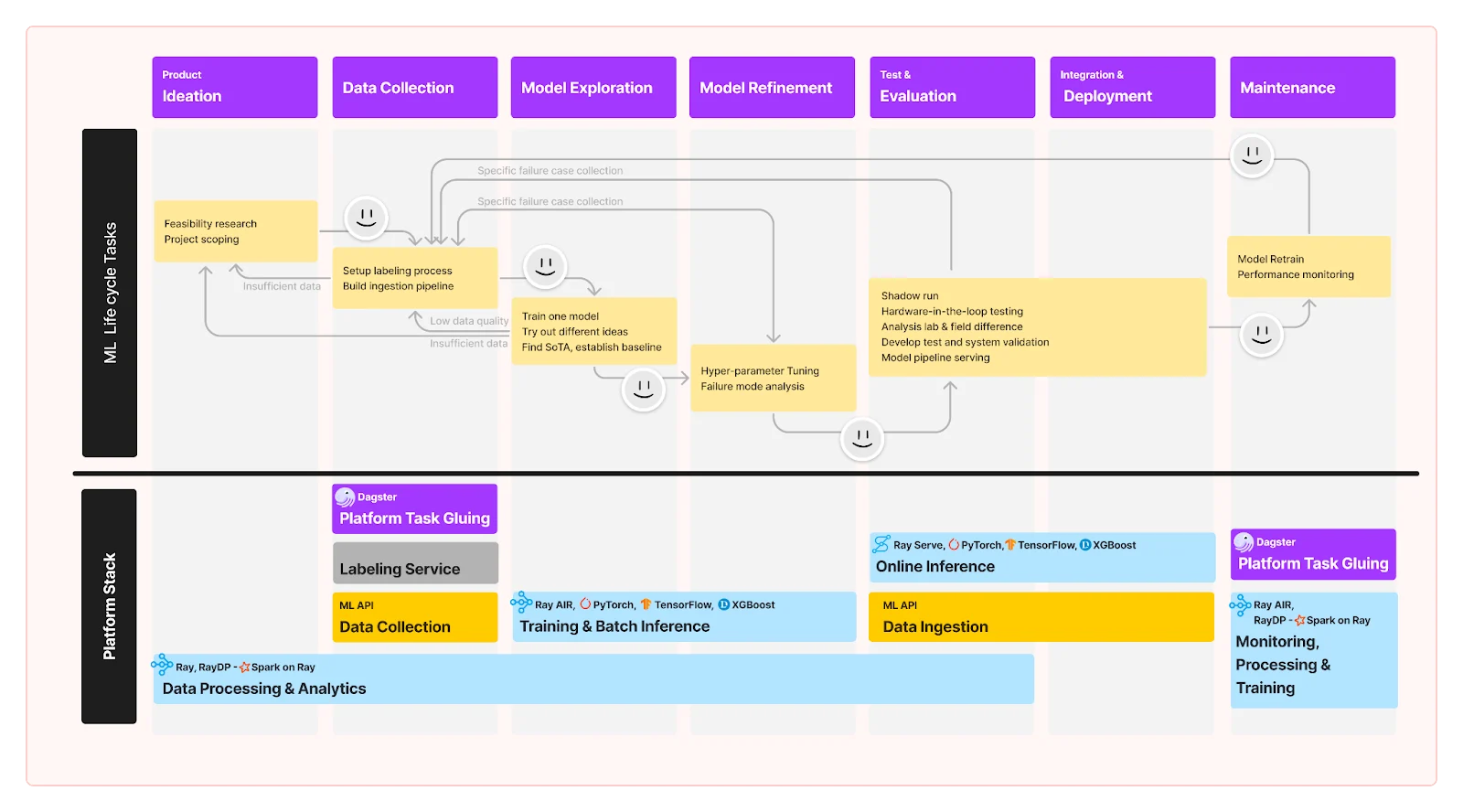
A typical ML development lifecycle and tools involved in Samsara AI
Following that spirit, we decided to build a machine learning platform with these goals in mind:
Enable a repeatable machine learning development flow that scales from the very beginning. Samsara handles millions of requests per day for IoT applications processing computer vision and sensor fusion model pipelines. In addition, to prototype new ML applications, we also need to work with large volumes of raw data securely and efficiently.
Ensure consistency of knowledge and minimize switching and long-term operational costs throughout the entire ML development lifecycle. Developers should be able to stay on one platform for most of their early tasks and glue tasks in later stages to interact with other platforms within the same codebase. Also, the platform should guarantee a path forward to optimize long-term operational costs.
Develop different levels of guardrails with observability for systems involved in the ML lifecycle that have strict stability or cost requirements. This includes logging relevant information like metrics and error traces to a place where scientists can derive insights programmatically at scale, using the same tool they use for ML development. This creates a feedback loop between production and experimentation systems, eventually enabling scalable self-service experimentation.
In this blog post, we’ll discuss how we achieve some of these goals by adopting Ray as the foundation of our ML platform, and walk through examples of how we use Ray’s ecosystem, including RayDP, Ray Tune, and Ray Serve to solve problems in our new infrastructure development.
Why Ray at Samsara
Overview of Ray
Ray is an open-source framework for scaling machine learning and Python applications. It provides a unified compute layer for parallel processing so ML developers don’t need to be distributed systems experts to write scalable code.
Ray plays a pivotal role in Samsara’s machine learning platform: With its efficient task scheduling, dynamic resource allocation, fault tolerance and rich ecosystem, Ray enables scientists to design and implement processes that inherently scale with the complexity of their models, effectively closing the gap between research and operations.
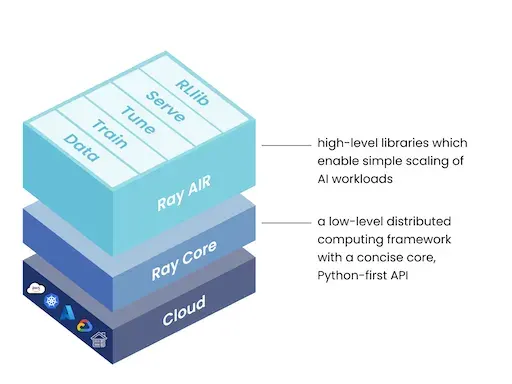
The components of the Ray framework [2]
How Ray helps Samsara ML development
Using Ray, we are able to quickly run inference with foundational AI models during product ideation. We can then gain insight into our data, bootstrap our labeling process, and kickstart new models with distillation. Ray allows us to quickly try out new models and scale our experiments up to hundreds of millions of image inputs. What’s more, the framework provides a cluster launching and job submission API that abstracts away the details of the low-level infrastructure. This makes it easy to translate the execution flow developed in early development into a formal pipeline governed by an orchestration system after the idea matures.
Data processing in a unified workflow with Apache Spark on Ray
In the early stages of Samsara’s ML development lifecycle, we observed that ML developers spend significant time on data preprocessing and training data ingestion, which are typically done under different frameworks (e.g., Spark for data processing, PyTorch for training). In a conventional setup, these frameworks are deployed in separate platforms, meaning machine learning developers have to rely on an external orchestration system and storage to stitch them together to create a working pipeline — even if all they’re trying to do is create a reusable training component for model exploration. Separating data processing from the machine learning platform also adds complexity to change management and data lineage tracking, especially for new projects.
RayDP (Spark on Ray) has helped us overcome these challenges. It combines the Spark and Ray clusters, making it easy to do large-scale data processing using the PySpark API and seamlessly use that data to train models using TensorFlow and PyTorch in a single Python script. The following is an example:

The above code will create a Spark cluster on top of Ray, with Spark executors scheduled as Ray actors. Configurations in the extra_spark_configs dictionary pin the Spark driver and executors on nodes with custom virtual resources spark_master and spark_executor. This feature contributed by Samsara, which gives users control over deploying Spark and Ray workloads in different worker groups to implement concepts like node affinity or achieve workload isolation.
Once the SparkSession is obtained, you can read data into Spark’s DataFrame format and further convert that into a Ray Dataset so it can be fed into the training job. For the sake of demo, we’ve borrowed the NYC Taxi XGBoost example from RayDP (the complete sample code can be found here):

Besides supporting data preprocessing, Spark on Ray plays a key role in machine learning observability and offline analytics stacks. The online machine learning system logs metrics and statistical data to the internal data lake via Firehose, which could in the future be queried by Spark on Ray at scale, helping machine learning developers gain insights into online production systems in near real-time.
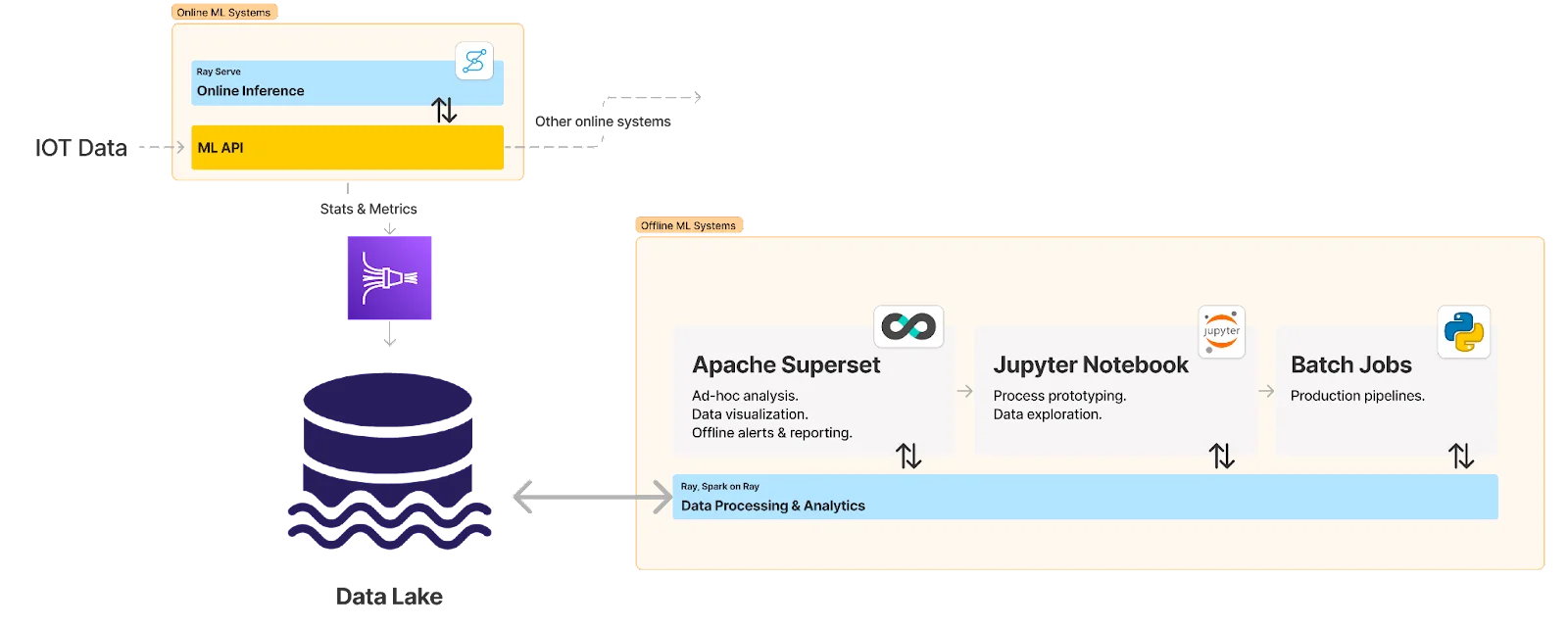
Combined with other tools, RayDP gives ML team a nimble but powerful stack to gain operational insight from production
Self-service orchestration with Ray and Dagster
While Ray is indeed a powerful framework for distributed computing and can combine many processing steps into a single script, there are still valid reasons why an orchestration engine is valuable in the context of complex machine learning workflows. Especially when the pipeline involves external steps like labeling.
Expressing workflow declaratively
At Samsara, we implement the workflow abstraction layer using Dagster to orchestrate Ray execution commands. Although Dagster provides easy-to-use APIs and comprehensive documentation, we found it still a bit involved to express a complex workflow using its imperative Python API.
Instead, we want scientists to be able to express the pipeline in a declarative manner, with the underlying orchestration infrastructure abstracted away. In this case, ad-hoc steps developed in early stages, like launching/terminating Ray cluster, and executing different scripts using command line could be formalized and versioned as code easily. This led us to create the Owlster package, a wrapper we use internally on top of Dagster. It allows scientists to define their workload as a simple no-code YAML file.
Here’s an example owlster file that creates an orchestration pipeline:

The pipeline comes loaded with all the bells and whistles, like alerting and scheduling. When deployed to Dagster, it’s tagged with the exact git commit that resulted in the current state of the pipeline, which makes lineage tracing and debugging so much more powerful.
Dependency inference and parameter interpolation
All the tasks for the pipeline are defined under the ops section. While building the DAG, the Owlster framework implicitly identifies the dependencies between tasks based on how to fetch args/configs for that task. For example, in the above pipeline, dataset_publishing_cluster and get_run_dates tasks don’t depend on any other tasks and thus are the starting point for the pipeline. The gen_training_data task, on the other hand, fetches cluster_ip from the output of the dataset_publishing_cluster task and fetches start and end dates from the get_run_dates task. If there is no argument dependency between two tasks, but you still want one task to occur before the other, you can list those tasks under the upstream section, as we’ve done for publish_to_labelbox and stop_ray_cluster.
The Owlster YAML will result in the following DAG:
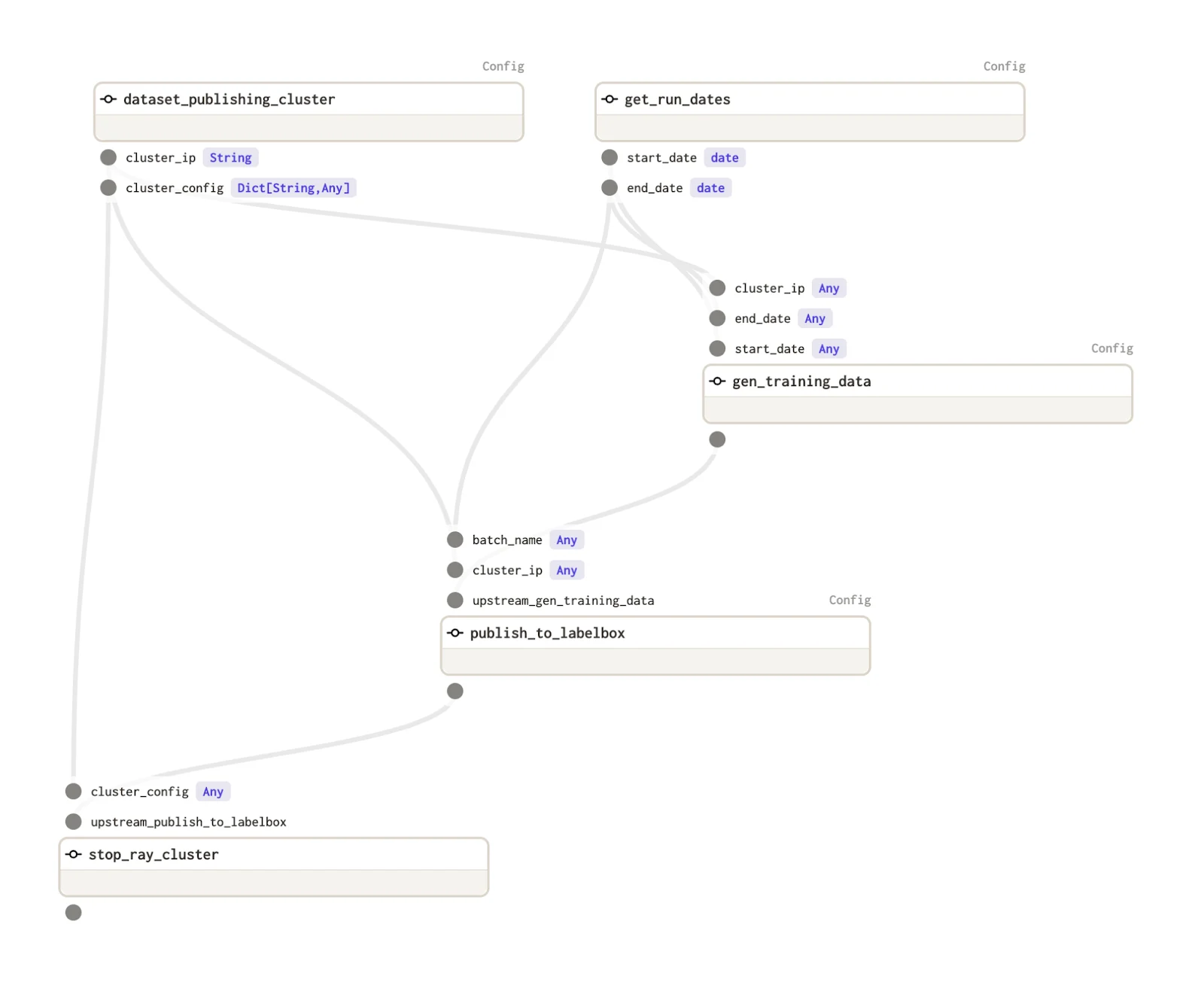
The framework also supports use cases where an argument is a combination of results from multiple sources, such as the batch_name in publish_to_labelbox. Owlster is smart enough to gather outputs from multiple sources and substitute them at runtime. Let’s say someone wants to add a new field to the dataset, like the start date for data capture. Typically, they would have to write a new function, which would take an extra argument, and append it to batch_name. With the Owlster framework, they just need to update the batch_name parameter in YAML to {context.run_id}-{get_run_dates.end_date}-{get_run_dates.start_date} and the framework will identify the new dependency, update the graph, and substitute the correct values during execution. This makes the development process much cleaner and faster.
Bring your own operator
Although most of the pipelines follow the launch cluster -> do work -> shutdown pattern, if a developer wants to do something very custom, they can easily define that logic in a Python function and register that function using the @OpBuilderFactory, register decorator. This will allow scientists to refer to those custom functions by name in the YAML and just specify where to fetch the arguments — helping us modularize and reuse repeated processes in the ML lifecycle. Here’s a basic Hello World example:
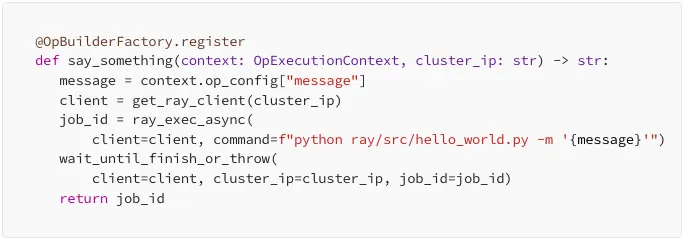
Hyperparameter tuning with hardware-in-the-loop using Ray Tune
Many of Samsara’s ML solutions run on our AI Dash Cams, which power safety applications for thousands of customers that preventatively detect risky driving behavior, like tailgating or mobile phone usage, and send in-cab alerts to coach and correct driver behavior in the moment. These cameras have operating characteristics that are very different from conventional cloud solutions. Unlike cloud instances, they run in power-efficient and compute-constrained scenarios. There are also factors relating to thermal footprint, latency, and memory that plague edge models more than their cloud equivalents.
Consequently, accurately profiling and optimizing our models necessitates tuning them on the device itself, to best match on-field performance. As a result, we needed a system capable of model tuning with the device-in-the-loop, so our camera platforms are best emulated. However, doing so at scale across hundreds of devices poses challenges:
Scaling memory and compute: Models, data shards, and metrics need to be asynchronously distributed across the device farm.
Observability: Experiments need to be trackable and debuggable. This involves collecting logs on model performance and system characteristics like thermals, compute, etc.
Runtime Selection: CPUs and GPUs are the least suited for our work. CPUs are too slow, while GPUs are too power-hungry to run our edge models at high frame rates. Digital signal processors, while being less flexible, are power-efficient. They require quantized 8/16-bit models to function.
Reliability: Having elastic and fault-tolerant processes is critical.
Pure parallelism isn’t enough: With a larger search space and limited on-device compute, brute-force searching isn’t feasible. We need a way to trade off algorithmic cost with efficiency and cleverly search the model space.
Ease of use: It’s not straightforward to implement and maintain solutions for the above. We were looking for out-of-the-box solutions for many of the search and parallelization challenges.
Broadcasting model selection to cameras
Bearing these constraints in mind, we’ve set up a framework to perform model selection and HPO using Ray. Our system allows for distributed training as well as tuning on devices. Below is a simplified view of what this looks like along with the accompanying configuration in Python. The key idea here is that our framework allows Ray worker nodes to reserve cameras and bring them into the worker cluster for scaled compute.
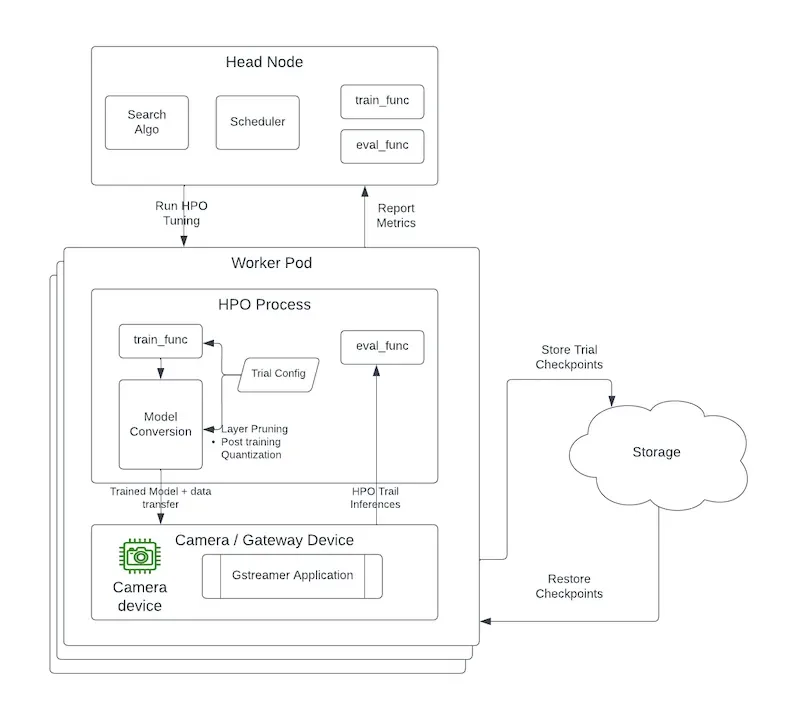

At runtime, Ray Tune automatically creates a trial for each hyperparameter configuration, and these trials are all run in parallel across the entire cluster. When training models, our worker nodes perform model evaluation and inference on the edge, an added overhead. In a conventional tuning process, only the worker nodes would scale based on the search space. At Samsara, however, we also allow for scaling of the cameras to facilitate on-device inference.
Trained models in workers are converted to SoC-compatible artifacts and shipped to the camera, along with the inference data. On-device applications are in turn spun up to run inferences and return the data back to the worker nodes. Some noteworthy aspects of this system are:
There are 10s of parameter settings that we need to explore before choosing the best model. We bank on Ray to do the orchestration of distributed trials.
We fan out trials to the worker cameras during the initial exploration phase and skip to the more promising configurations based on the results along the way. By pruning the underperforming trials, we save time and compute resources.
Ray leverages all of the cores and runtimes on our devices to perform parallel asynchronous hyperparameter tuning.
With Ray Tune’s built-in trial migration and cluster autoscaling, we can deploy our models and data to many devices and reduce model-tuning costs significantly.
Bridging the gap from development to deployment with Ray Serve
Historically, Samsara’s ML production pipelines were hosted across several microservices with separate data processing, model inference, and business logic steps. Split infrastructure involved complex management to synchronize resources, slowing the speed of development and model releases.
Ray Serve, and its intuitive model composition API, have allowed us to simplify our production ML pipelines by providing a common API for data processing, model inference, and business logic tasks through the worker pool, while also allowing for specialization, such as hardware acceleration with GPUs.
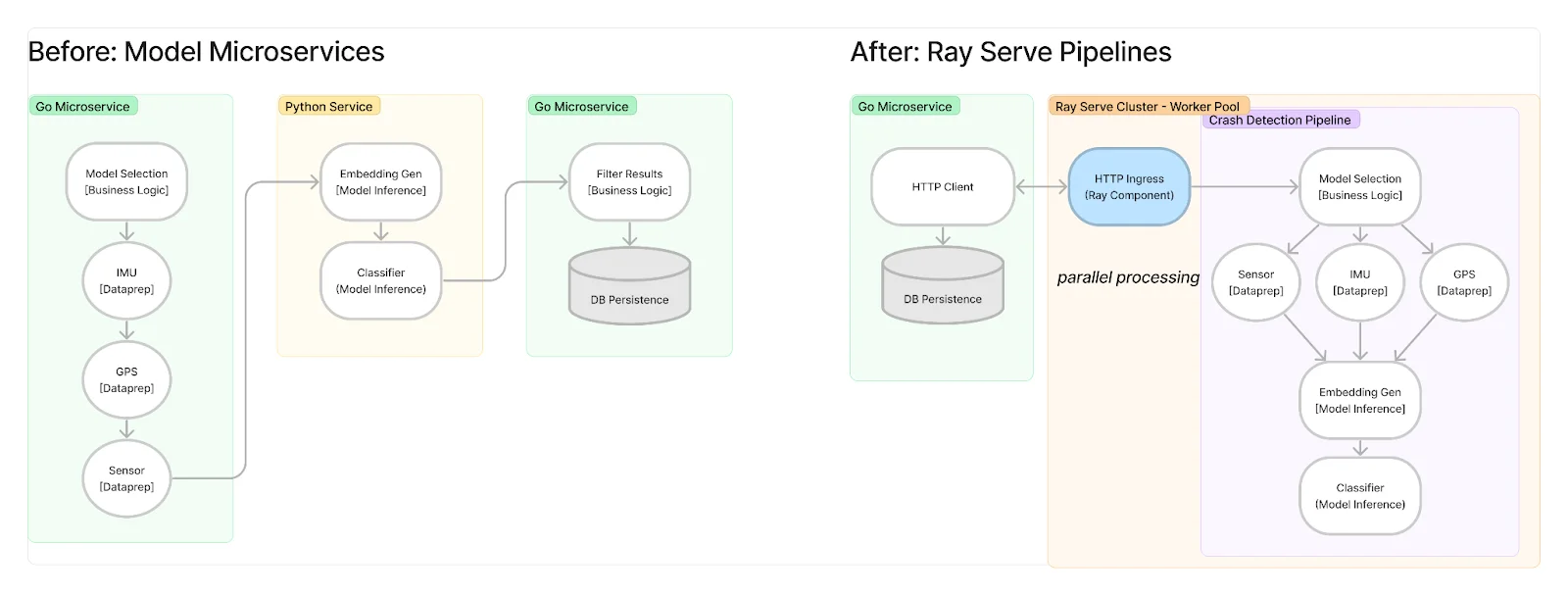
Introducing Ray Serve dramatically improved our production ML pipeline performance, equating to a ~50% reduction in total ML inferencing cost per year for the company. As an asynchronous, distributed computing platform, Ray Serve allowed us to maximize our CPU utilization for cost efficiency and use non-blocking I/O calls to reduce latency. Using Ray Serve’s profiling tooling, we observed that bottlenecks often involved moving and transforming data. Localizing data processing in the same pipelines as model inference improved efficiency and simplified the codebase relative to alternatives explored, such as model inference endpoints.
Additionally, Ray Serve’s APIs offer the unique advantage of consistency with offline development for teams already using Ray. Concepts such as tasks and actors are the same, reducing the learning curve to take models from training to production. While switching from Ray’s cloud VM deployment for development to Kubernetes-KubeRay in production, the underlying compute backbone is abstracted away. As such, applied scientists at Samsara can contribute to application development without a handoff to ML engineers.
Conclusion and Future Work
In the past year of development, we already see the benefit of the new platform: Teams can deliver AI features faster, with lower costs and better performance. Qualitatively, scientists are also having more fun because they’re empowered to own their projects from start to finish and easily contribute scalable, production-ready code across the ML lifecycle. We still have more work ahead, namely:
Continuous Training: A major chunk of scientists’ time spent on re-training models is finding adversarial data samples where the existing models do not perform well. Building capabilities around smart data sampling and continuously re-training with adversarial examples ensures production models are always up-to-date and improving.
Model Registry and Lifecycle Management: To close the loop on continuous training, we will provide a simple interface for scientists to manage model rollout and observe performance through shadow deployment to production.
Further Optimizing Cost-Efficiency: Ray Serve provides optimizations that we’ve yet to take advantage of. For example, simple request batching combined with hardware acceleration provides more multipliers, reducing inference costs and latency.
Driving Operational Excellence: Samsara has a strong culture of operating what we own. We will ensure high availability of our services through canary deployments and blue/green cluster setups.
We’re going to be speaking at Ray Summit 2023 to share even more details about our ML platform. Come check out our session on Building Samara’s Machine Learning Platform with Ray and Ray Serve for IOT @ Samsara — we hope to meet you there!
Lastly, Samara’s ML Modeling and ML Infrastructure teams are growing! If you are interested in projects like these, check out our open roles here.
Thanks to Brian Westphal, Phil Ammirato, Saurabh Tripathi, and Sharan Srinivasan, who also contributed to this post.
Notes, References, and Image Credits
[1]. Eric Colson, https://multithreaded.stitchfix.com/blog/2019/03/11/FullStackDS-Generalists/
[2]. Image source: https://docs.ray.io/en/latest/ray-overview/index.html#ray-framework
