Engineering at Samsara
Improving CI/CD with a Focus on Developer Velocity
September 16, 2022
Senior Software Engineer

Get the latest from Samsara
Subscribe nowWhen you think of software scalability, what comes to mind? Maybe sharding a database or load-balancing requests over multiple servers. But how often do you think of scaling the process of testing and merging code?
As Samsara scaled in engineers and our product grew in complexity, we had to figure out exactly this problem: how to scale our continuous integration (CI) system. Because we have a monorepo, our CI is prone to getting bloated with complexity very quickly—we’re running frontend tests, Go tests, Python tests, service building checks, linters, and much more. As a result of this bloat, more failure modes emerged, and engineers often wasted time debugging or retrying failed CI runs. An unreliable CI system blocks engineers from merging and deploying code, which can be particularly disastrous if there is an outage.
There are many things you can optimize for with CI, but as we looked at how to scale our system effectively, the main principle that guided our tradeoffs was developer velocity. An efficient product development lifecycle is critical to Samsara’s business—it allows us to quickly ship products and iterate on them based on customer feedback.
In this article, we’ll discuss CI scaling issues that we suspect other monorepo-running tech companies may encounter. We will explain solutions or mitigations that have proven to be successful in improving developer velocity at Samsara, so that you can walk away with actionable insights. Specifically, we’ll cover:
What makes CI unreliable?
The merge race problem, and merge queue as a solution
The flakiness problem and solutions
Merge races revisited
What makes CI unreliable?
You might be wondering, if every PR needs to pass CI to be merged into the “main branch”, how can main ever fail CI? The failure modes can be grouped into two buckets:
Merge race conditions happen, where it’s possible for two PRs to have a conflict in main, even though they both passed CI independently.
Flaky tests/infrastructure causes an otherwise healthy main to seem unhealthy.
Between the two, we found merge races to be extra painful. A CI run that flaked can just be re-run, but merge races would break main and require an engineer to merge a PR to fix it. These breakages would often last for hours, causing pain for developers.
Let’s demystify what a merge race is.
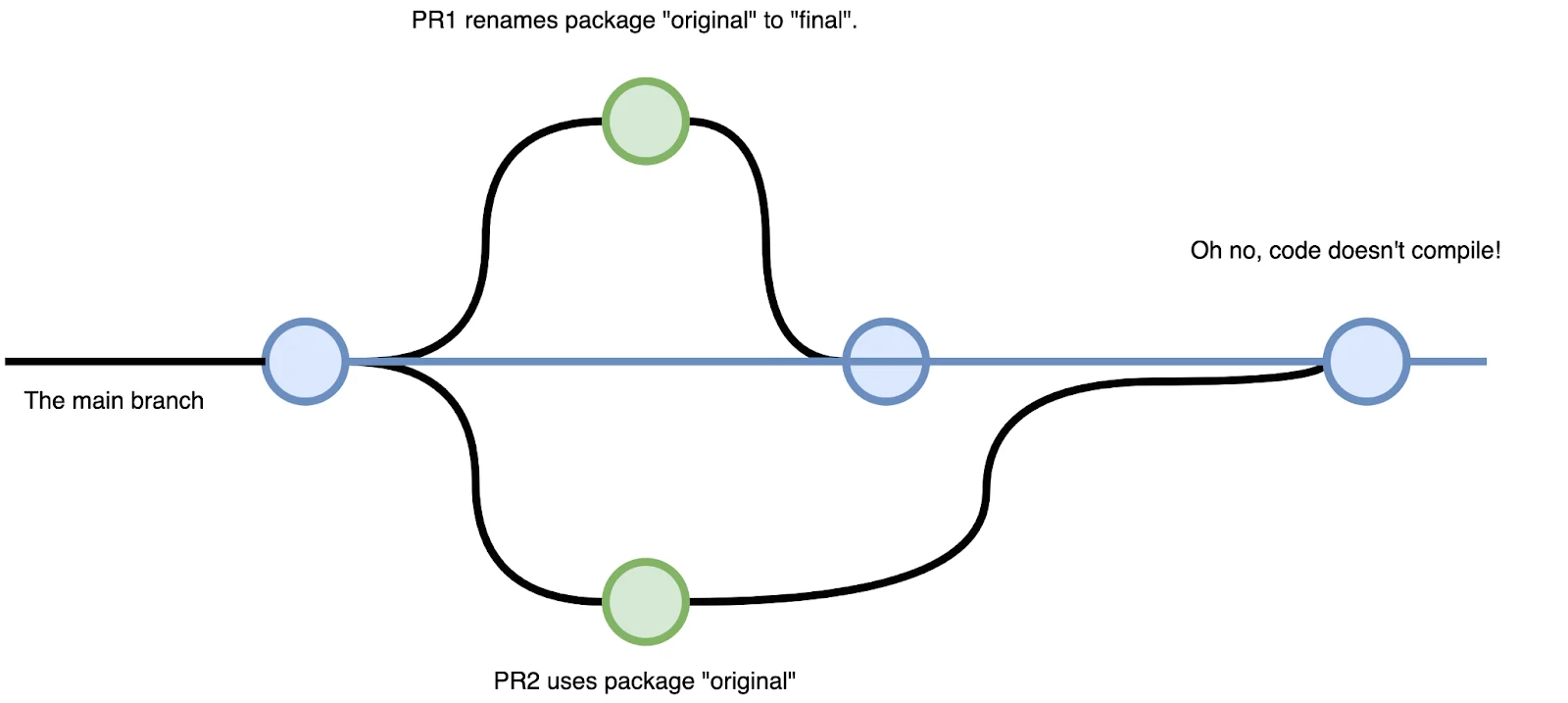
The merge race problem
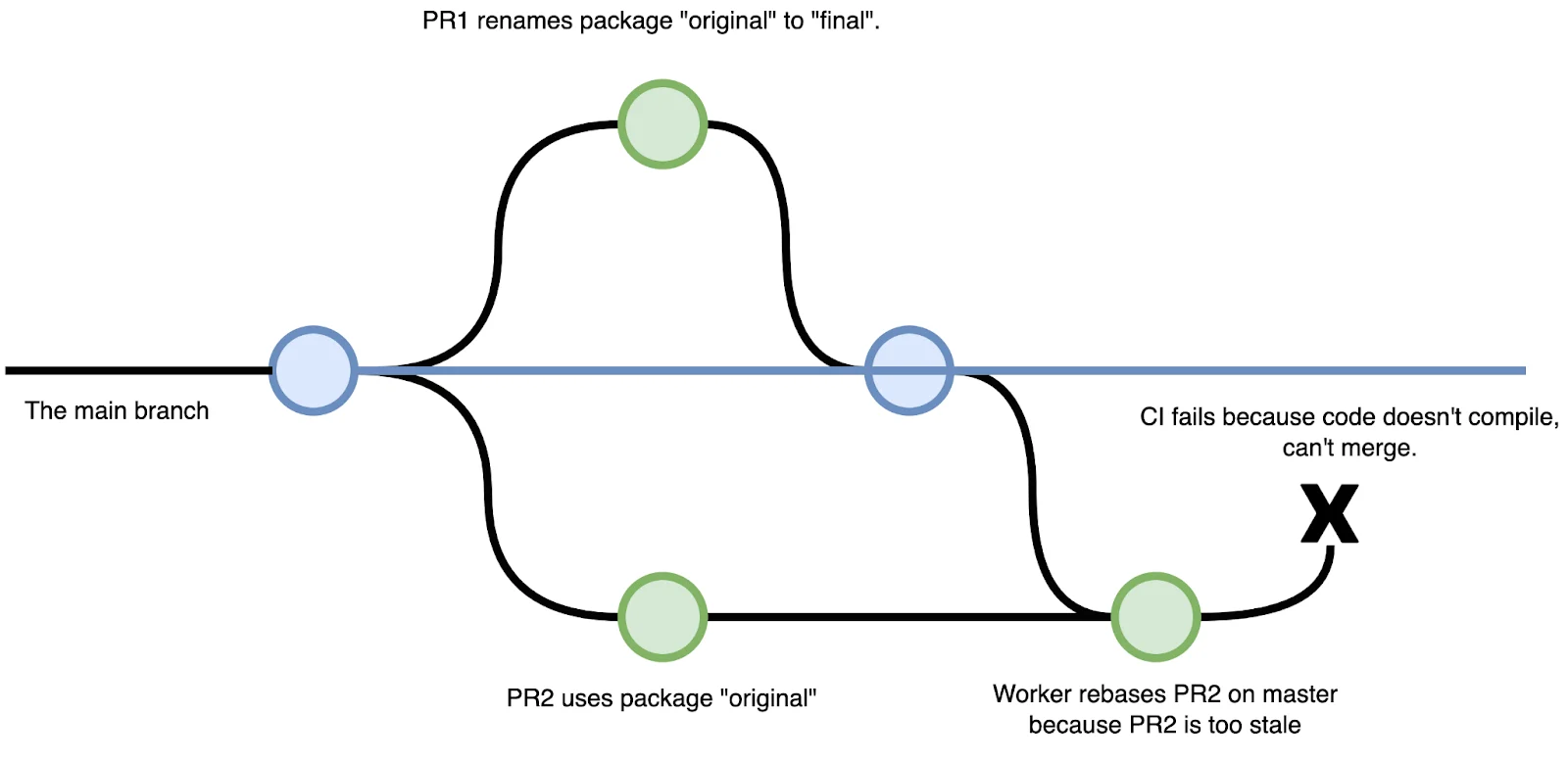
When multiple people are putting up pull requests and merging into main, the likelihood of a merge race increases. Here’s an example:
PR1 renames package original to final. CI passes.
PR2 adds logic that uses package original. CI also passes.
PR1 is merged into main.
PR2 is merged into main. The code fails to compile because package original no longer exists, it’s been renamed to final.
main is broken until somebody puts up a PR to fix the issue, either by reverting one of the PRs or opening a new PR.
Just like any concurrency problem, if we serialize writes (merging) to the critical section (main branch), we will be safe from merge conditions. A merge queue accomplishes exactly that.
Merge queues: A solution with trade-offs
PR A ← PR B ← PR C (your PR)
A merge queue is exactly what it sounds like: instead of merging directly into main, your PR gets placed on a queue of PRs, and the queue merges changes into main one at a time.
At Samsara, we rolled out a merge queue back in 2019, but we found it more painful than helpful and soon reverted it due to the negative impact on time-to-merge.
We realized a merge queue exacerbates CI flakiness because if a PR A in the queue fails (due to flakiness or a legitimate issue), it will be kicked out of the queue and all PR’s behind PR A will abort their current runs and start a new CI run. If there are many PR’s ahead of yours in the queue, and many are failing, it may take many (partial) CI runs for your PR to actually get merged, and of course, your PR runs the risk of flaking itself, leading to greater frustration.
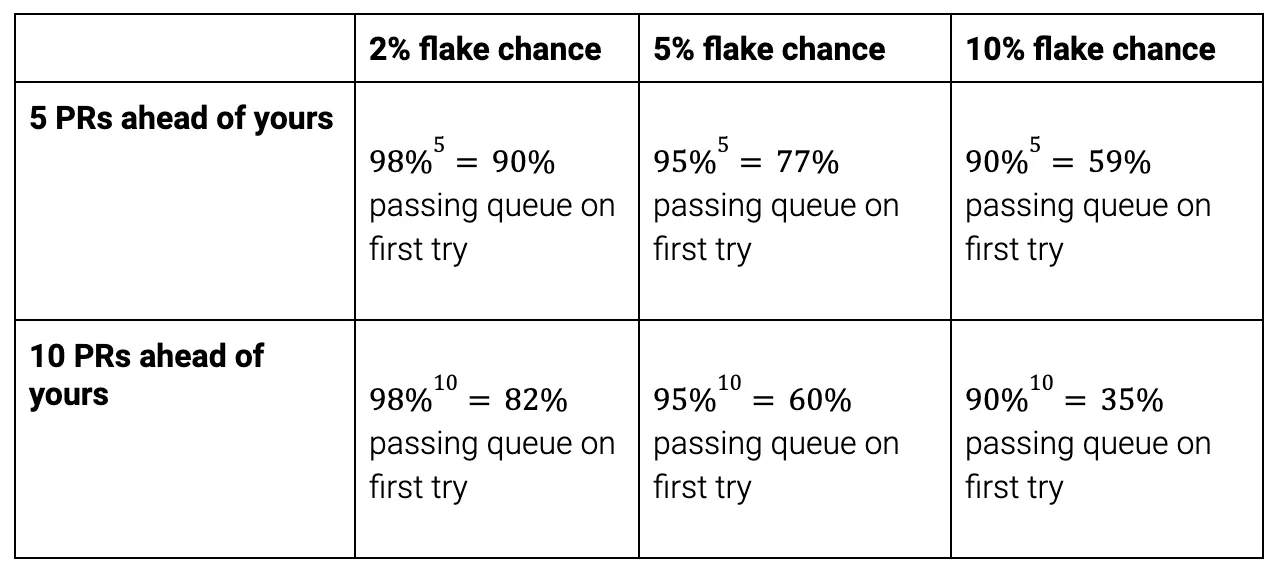
PR Note that even with zero flakes, a merge queue inherently increases CI time. Before adding the PR to the merge queue, it has to pass CI because we want to avoid polluting the queue with broken PRs.
Run 1: Put up PR, run CI. If it passes, you can add it to the merge queue.
Run 2: The PR rebases on the queue and runs CI again at least once, possibly more times due to PR’s ahead of it failing.
As we scaled into 2021, with merge races becoming more and more frequent, we decided to revisit the merge queue implementation. However, experience taught us that in order for a merge queue to be a net positive on developer experience, we would have to tackle two things first: flakiness and CI speed.
The CI flakiness problem (and mitigations)
At Samsara, we’ve seen flakiness come in all shapes and sizes.
Upstream dependency flakiness
If we make a network call in our CI to some upstream dependency, our CI reliability is going to be upper-bounded by the reliability of every upstream dependency.
This is why it’s best to limit the number of dependencies. How? Here are some things that we do at Samsara:
We use Yarn offline mirroring to install node_modules from tarballs stored in our Git repo so that we aren’t downloading dependencies from the network each time.
Vendor our Go dependencies into our Git repo.
Bake as many dependencies as possible into the Docker image that we use to run CI jobs.
Test flakiness
It’s natural that if your codebase is running thousands of tests, a few of them will be flaky.
At Samsara, we typically see tests flake because of:
Race conditions between execution threads
Time-based sensitivity in tests, ex. not using a mocked clock
Lack of sorting non-deterministic data structures
There is plenty of existing literature on unit test flakiness causes, such as this post from Checkr, so instead of focusing on the causes, we’ll talk about our mitigation processes.
We’ve found that a mixture of proactive mitigations and reactive mitigations are necessary to manage test flakiness at Samsara.
CI test grinder (proactive)
Whenever a test is introduced into the codebase, we grind (run) the test 10 times to try to catch any flaky tests before they get merged into main. Ideally, we’d grind every test on every CI run to ensure that flakiness was not introduced to existing tests as well, but then it’d make our tests 10x slower, which wasn’t worth the tradeoff.
We also attempt to grind existing tests that have been touched directly in the branch by examining the Git diffs between the branch head and the main branch merge-base. Of course, there are many ways for a test to become flaky without being directly touched, but it’s still proven to be helpful.
To be clear, test grinding is just the first line of defense. We found that some tests flake <0.1% of the time, so for those cases, even if you grind it 100 times, there would only be a 10% chance that you would catch it. That’s why reactive measures are necessary too.
CI reliability report cards (reactive)
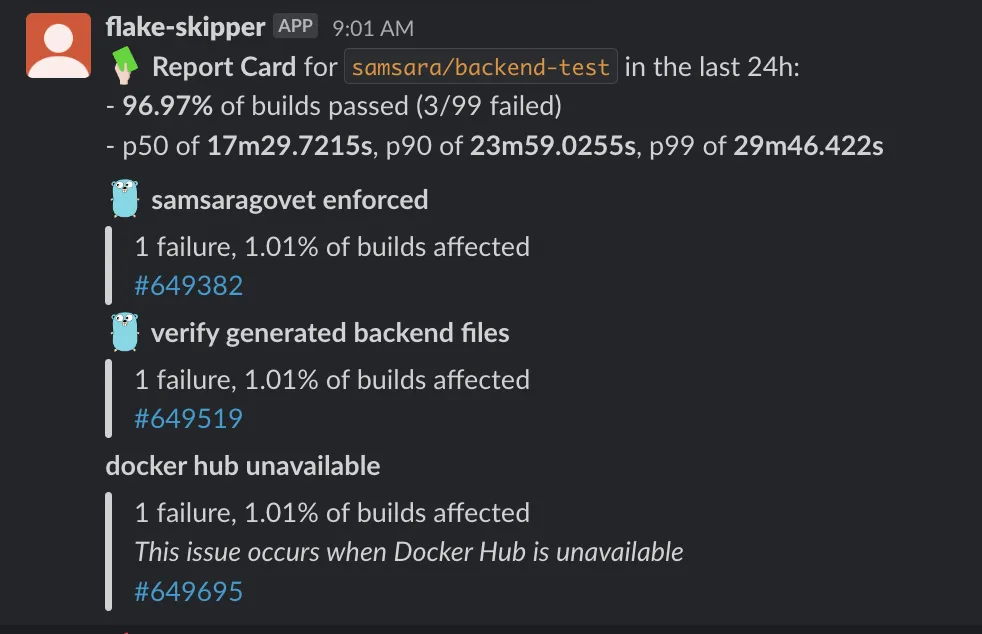
We have a daily cron that analyzes all the CI builds for the main branch from the past day, finds the builds that failed, and then will look over the logs to parse out the specific jobs that failed. We can even pattern match on specific error logs to provide more context.
We then post the resulting “report card” into a Slack channel for visibility. CI owners can glance at which jobs failed and drill in for more detail if necessary.
Automated flaky test skipping (reactive)
We run a cron that will look over the logs of every CI build and check for Go test failures (we upload JUnit files which are easily parsable).
If, for a specific test, we find a pattern of pass → fail → pass, then we automatically generate a PR to skip it. JIRA tickets are generated for every flaky test and assigned to owning teams.
Selective testing (reactive)
Recall that Samsara is a monorepo, which means that we by default run a plethora of CI checks for each branch, even if a developer’s changes are typically limited to a specific domain. In reality, if a PR only touches frontend code, there should be no need to run Go unit tests.
With that thought, we introduced logic that looks at a PR’s changed files, and matches those files with a set of glob → CI check mappings to determine which checks need to be run.
In addition, we statically analyze the import graph of our codebase to detect which test suites need to be run. If a Go service A was changed, and Go service B does not depend on A at all, there’s no need to run B’s tests.
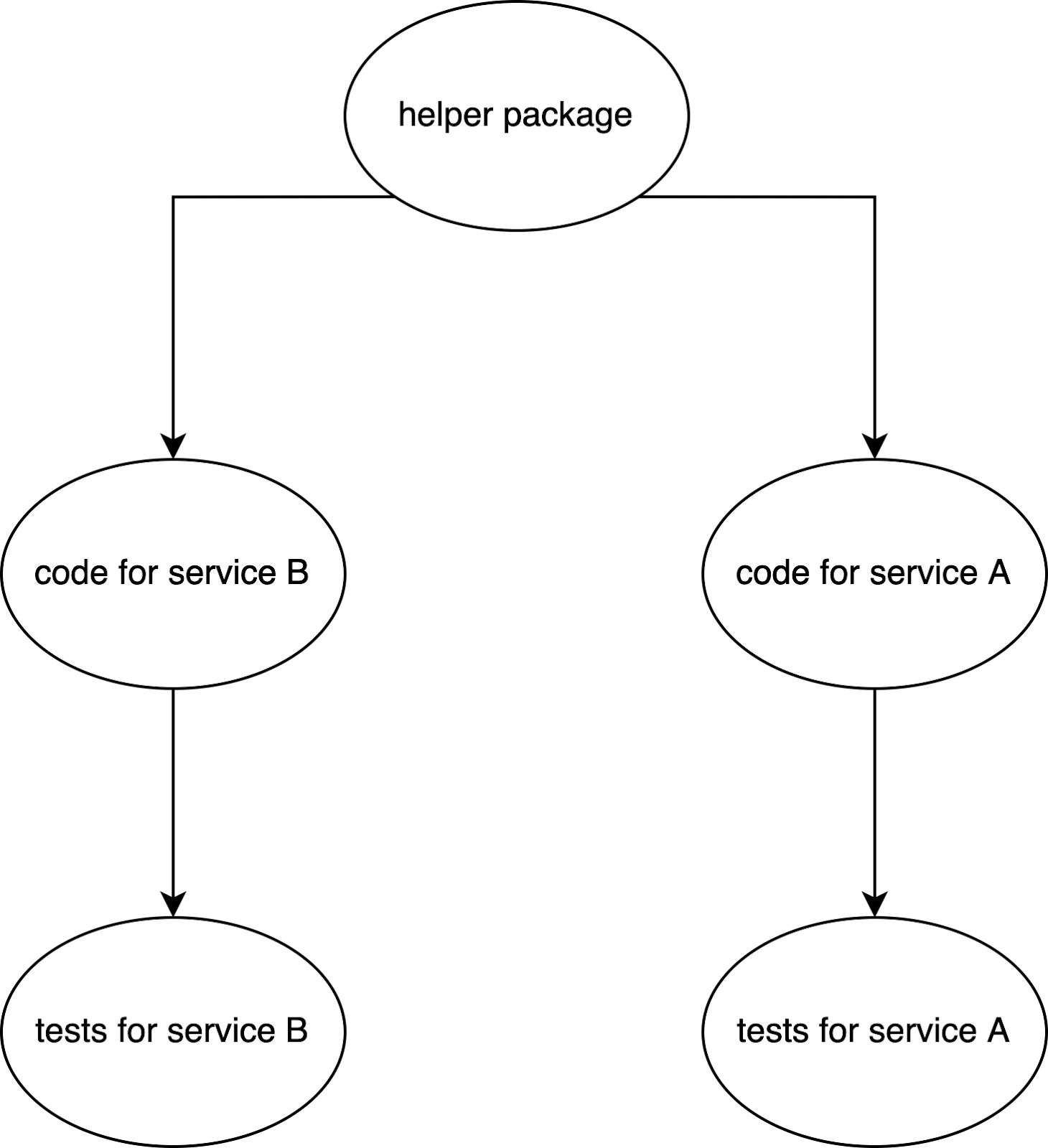
Note that selective testing reduces the chances of flakiness. Imagine having a test that flakes 50% of the time, but only half the CI runs actually trigger the flaky test. It’s effectively only flaking 25% of the time now!
Philosophically, selective testing gives a monorepo CI some of the reliability and isolation of a polyrepo while maintaining the simplicity and cohesiveness of a monorepo.
The CI speed problem (and mitigations)
As our codebase grew, CI became increasingly slow. This was very painful for developers who were iterating on their PR and frustrating for developers who ran into a CI flake. And, as mentioned before, slow CI was one of the reasons that costs of implementing a merge queue outweighed the benefits.
The main culprit behind the CI slowdown was our enormous Go test suite. From 2019 to 2022, we were pleased to see the number of unit tests increased by 5x. Selective testing (mentioned in the previous section) helped us keep our CI speed down. By only testing the packages that were touched by a PR, we could run fewer tests. Still, some PRs ended up touching a frequently imported package, and would cause us to run the entire Go test suite.
To improve performance in these cases, we parallelized the testing of packages across different CI-job-running shards. We found that the shards would become unbalanced—a shard would be unfortunate enough to be tasked with testing multiple Go packages that had long test times. As a mitigation, we began collecting historical metrics on each package’s test time and then used the metrics to fairly distribute package testing across shards.
At the same time, a few of our Go packages began having test times of longer than 10 minutes, which means that no matter how well you parallelize, the longest shard will take at least 10 minutes. To address this, we added some logic to break our longest-running Go packages into multiple chunks, so that a single Go package could be distributed across different shards.
Parallelization did wonders for CI times, but it’s no silver bullet.
Parallelization means paying for speed with money (more EC2 instances)
Parallelization will plateau on the longest-running operation (see Amdahl’s Law). Even if we could afford to run 1000 shards, each shard would have to perform CI job setup (preparing the Git repo, setting up the Docker environment), compile the packages it’s tasked with testing, run the tests, emit test metrics, and do the CI job cleanup
Nevertheless, with these efforts, we were able to keep our CI the same speed as it was in 2019, even though the number of Go tests has 5xed.
Revisiting merge races
By early 2022, our flakiness was around 2%, and our CI speeds had stabilized around 15 minutes. Circling back to the idea of (re)introducing a merge queue, 15 minutes of CI would become 30 minutes of CI, which isn’t terrible, but also not great. This gave us pause. Development speed is highly valued at Samsara. We wanted to get back the time we were spending fixing merge races, but we weren’t sure if doubling CI time was worth it.
The middle-ground solution
While a merge queue guarantees a healthy main branch, we felt like we didn’t need guaranteed main health, especially if it meant a net loss of productivity in CI-waiting time. So, we implemented a middle-ground solution: automatic rebasing of risky PRs.
To determine which PRs present a merge race risk, we use a heuristic based on base commit age. Our rules are currently:
If creating or pushing to your PR, we will automatically rebase your PR for you if its base commit is more than 12 hours behind main’s HEAD commit. This all happens in seconds so that it’s barely noticeable, which is why we can rebase more aggressively without impacting developer velocity.
When merging in your PR, we will automatically rebase your PR for you if its base commit is more than 72 hours behind main’s HEAD commit.
Our automatic rebasing is implemented by a webhook-based worker that listens to GitHub PR-related webhook events.
Returning to the merge race example from earlier, when PR2 is created, GitHub would send a webhook event to the worker and the worker would evaluate whether the PR is a merge race risk. If so, PR2 would be automatically rebased. To the author of PR2, there is a negligible amount of extra CI time, but it also drastically reduces the chances of a merge race breaking main.
Conclusion
As a result of two years’ worth of adding monitoring, building tools, and testing hypotheses, we were able to get our CI reliability into a healthy state.

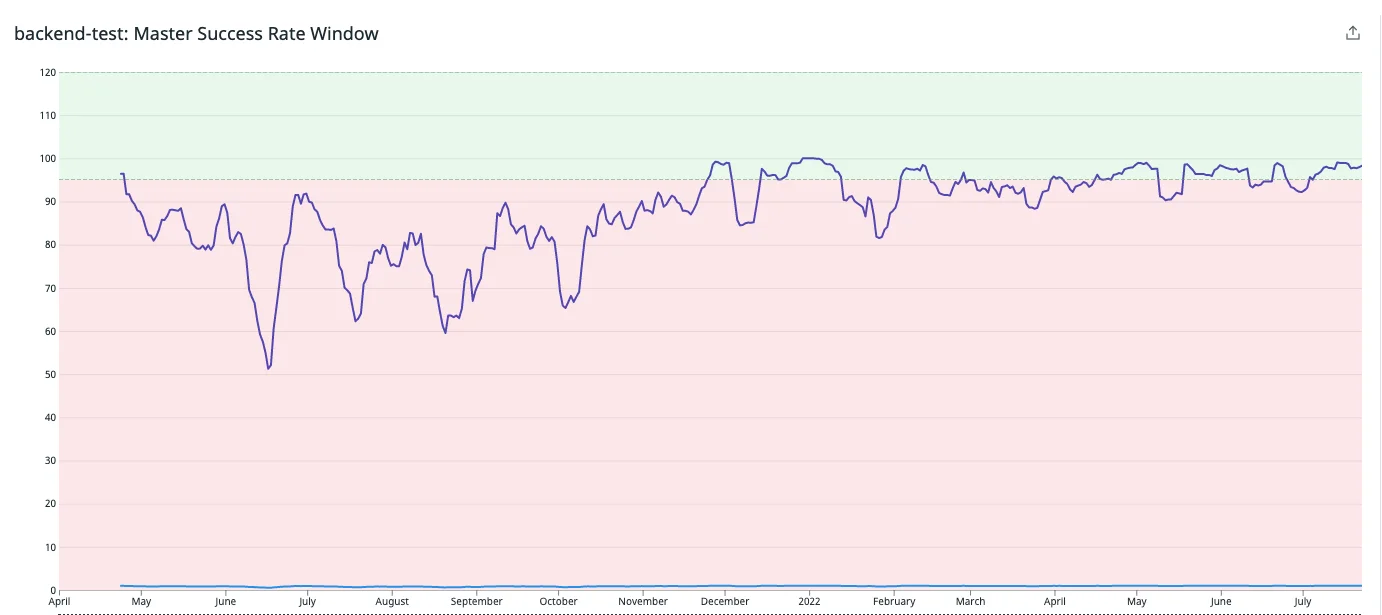
CI reliability from 2021 into 2022
It’s important to think honestly about the dimension you’re optimizing for. If we were purely optimizing for CI reliability (which seems like a good idea at first glance), we would have implemented a merge queue—but this would have come at the expense of CI runtime. We decided that overall developer experience/velocity is the end goal, and we were able to pivot away from the merge queue to the middle-ground solution.
We hope that this post discusses relatable challenges that many growing tech companies will face and that some of our learnings can be of use to you. If this kind of work sounds interesting to you, we’re hiring and would love to hear from you!
Get the latest from Samsara
Subscribe now